営業:平日8:00~17:30 定休日:土日祝
PDFのOCRテキスト認識による文書検索の活用法とは?
PDFのOCRテキスト認識とは
OCRテキスト化の特徴
圧倒的な速さが決め手
- スキャンした原稿の文字情報を機械的にPDFの中から拾い出して透明テキストとしてPDFファイルの中に埋め込みます。
- 人間が読み取って手入力するのに比べて圧倒的に速いため、低コストで検索システムを構築出来ます。
- 書類の中から必要なキーワードが含まれている箇所を探し出す必要がある場合におすすめです。
フリーソフトのダウンロードで準備OK
- Adobe(アドビ)社のフリーソフトAcrobat Reader(アクロバットリーダー)の検索窓にキーワードを入力するだけで全文検索することが可能です。
- 操作が簡単なため誰でもすぐに利用することが出来ます。
全文検索機能を備えたOCRテキスト認識が導入されたケース
- 工場の図面を含む文書ファイル
- 官庁の各種永年保存資料
- 医療関係の論文
- 教育現場で用いられる指導書
導入が簡単でも優れた検索機能
①「簡易検索」機能
キーワードを入れてエンターキーを押すだけ
専門的な知識は一切不要です。検索したキーワードからキーワードへジャンプしてハイライト表示されるので、該当箇所を誰でも簡単に見つけることが出来ます。

①電子化されたPDFファイルをアクロバットリーダーで開きます。
②アクロバットリーダーのツールバーにある虫眼鏡アイコンをクリックし、現れた検索ボックスに任意のキーワードを入力します。(Adobe Acrobat Reader DCの場合)
③エンターキーを押すと検索窓に(1/63)のように該当する語句の文書内の数量が表示され、該当するキーワードが全てハイライト表示されます。
④エンターキーを押すごとに次の候補にジャンプして次々に移動していき、(2/63)、(3/63)・・・と数字が変化して表示されます。1ページが終わると次の該当ページに移ります。
⑤文書内の目的箇所が見つかるまで続けます。
②「高度な検索」機能
機能強化されても、いたってシンプルで簡単
完全一致、部分一致、しおりを含めるかなど、「簡易検索」に比べると検索条件を細かく指定できます。
高度な検索のその他の特徴
- 検索結果の一覧リストにキーワードの前後の文章も合わせて表示されるため、より簡単に探している箇所を見つけられます。
- 検索結果一覧が別ウインドウに表示されるため、PDFのウインドウを次々と開いて確認することが出来ます。
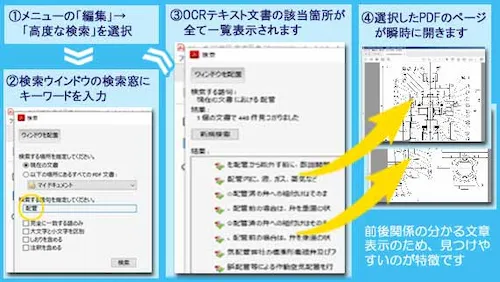
検索結果の一覧リストをクリックすれば該当ページにジャンプします
①アクロバットリーダーのメニューの「編集」→「高度な検索」を選択します。(Adobe Acrobat Reader DCの場合)
②検索ウインドウが開くので検索窓に検索ワードを入力し、「大文字と小文字を区別」などの詳細オプションを決め、検索ボタンを押します。
③検索ウインドウ内にファイル内の全候補が、前後の文章と共にリスト表示されるので、気になる候補をクリックします。
④該当PDFファイルが開くので、後は探しているページが見つかるまで、リストの候補箇所をクリックするだけです。
PDFのOCRテキスト認識における注意点
カラー原稿モノクロ原稿を問わず、テキスト情報を利用可能
JPEG画像、TIFF画像ともにテキスト情報を付与出来ます
- カラーやグレースケールのJPEG形式、モノクロのTIFF形式ともにPDFに変換しながらテキスト情報を付与します。
- すでにPDF形式になっているファイルにも、後からテキスト情報を抽出して付与することが可能です。
OCRが苦手な文字があります
パターン・特徴のある誤変換
機械的に自動変換するためどうしても誤変換が発生したり、文字として認識できない箇所が生じるのがOCRのテキスト変換(テキストの埋め込み)だということを予め理解していただく必要があります。
PDFのOCRテキスト認識が困難なケース
- 手書きの文章
- 段組が複雑な文章
- 印字が薄かったり、文字の周囲が汚れている書類
- 『』などの記号・特殊文字・一般的ではない記号
- 和文の中に混在する英文字列
- アンダーラインの引かれた文字
- 表の枠組みの中の文字
- 横書き文章の中の部分的な縦書き文字
OCR技術の飛躍的な向上
日進月歩のOCR技術
近年OCR変換の技術は10年前に比べて飛躍的に向上しており、本文の日本語の漢字・ひらがな・カタカナについては、検索機能をお使いいただく上で差しさわりがないレベルでの文字認識が可能となっています。
さらに現在テキスト認識出来ない書類でも将来的には問題なくなる可能性を秘めています。ですから実際にテキスト付きのPDFに電子化されたお客様の中には、来るべき将来に備えてJPEGやTIFFの画像も保管されていらっしゃるケースもあります。
識字率が向上し、より精度の高い検索システムが構築出来る日はそう遠くないからです。